
Small Language Models Deliver Big Value: The Startup Founder’s Playbook
Not every problem requires the horsepower of a frontier Large Language Model (LLM). For many business applications such as classification, summarization, intent detection, and structured data handling, smaller models are sufficient and far more cost-effective. They are also often designed to be fine tuned, which lets startups create domain-specialized models that outperform generic LLMs on narrow but high-value jobs.
Small Language Models (SLMs) are built with fewer parameters, often under 10B, compared to the 70B+ or even trillion-parameter LLMs. Where LLMs aim for broad reasoning and versatility, SLMs are deliberately compact, faster to run, and easier to adapt. Companies like Meta (LLaMA-2 7B and LLaMA-3 8B), Mistral (Mistral 7B and Mixtral MoE), Microsoft (Orca), and Google (Gemma 2B and 7B) have released strong SLMs that can be fine tuned efficiently on modest hardware.

Comparison of LLM’s to Small Language Models
1. Match Tasks to Model Scale
NVIDIA’s research shows that agent-style workflows like routing intents, extracting structured data, and applying business rules do not need the full weight of a frontier LLM. SLMs are often sufficiently powerful, operationally superior, and far more cost-effective for these tasks.
A hybrid architecture, where SLMs handle predictable tasks and only escalate to LLMs when complexity or nuance demands it, creates a scalable, cost-efficient, and resilient AI stack.
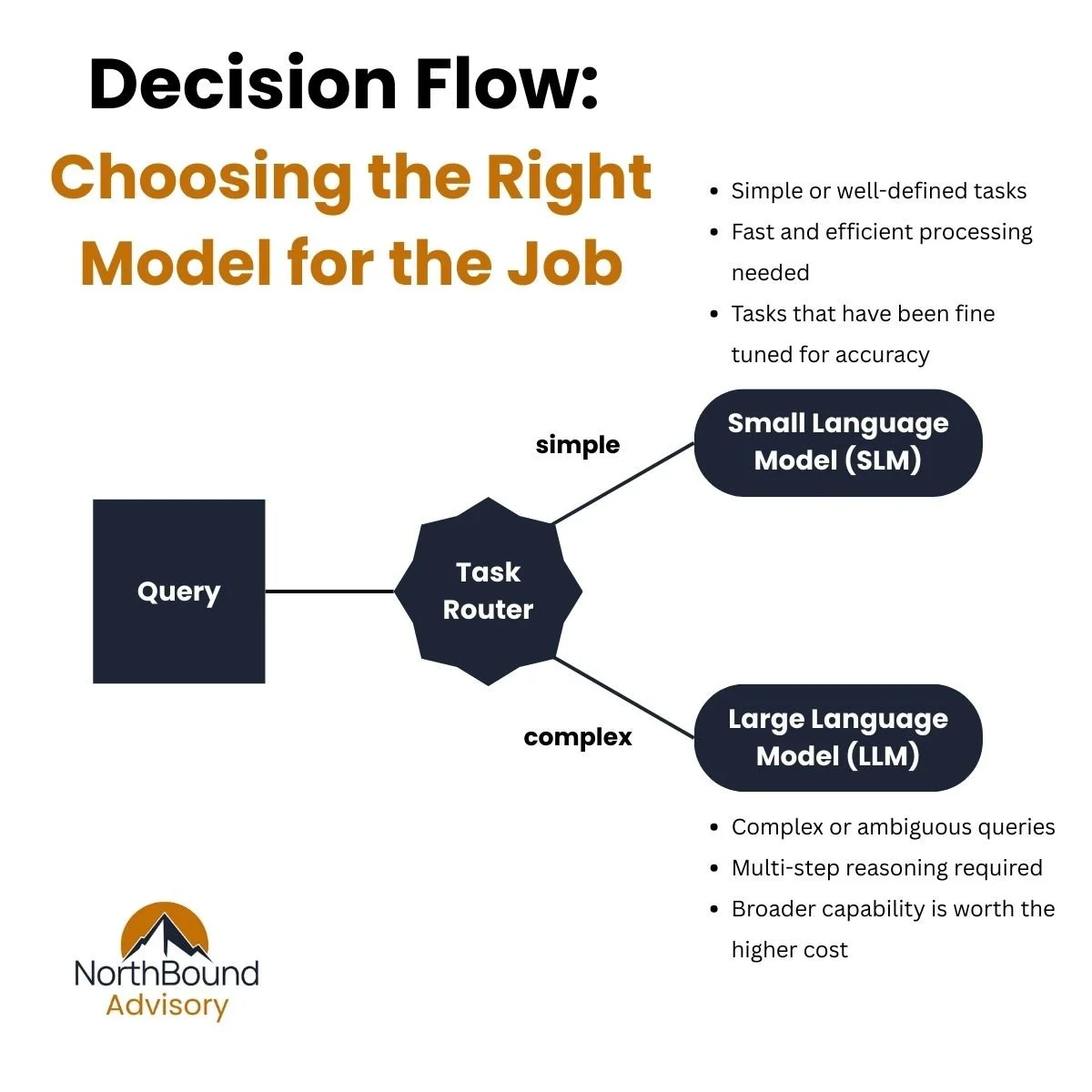
The right model for the task at hand
2. Fine Tune SLMs for Critical Customization
SLMs shine when fine tuned for narrowly scoped but high-value tasks. Techniques such as Parameter-Efficient Fine Tuning (PEFT), including LoRA and adapter tuning, allow startups to specialize models with minimal compute.
Studies show that fine tuned small models consistently outperform zero-shot large models on classification tasks across domains. New strategies such as Solution-Guidance Fine Tuning also enhance reasoning in small models with relatively modest training data.
Real-world examples prove the point. Cohere’s fine tuned Command R model delivered better summarization and domain analysis than GPT-4 at a fraction of the inference cost.

Popular SLMs in 2025
3. Why This Matters for Your Startup
Preserve runway. Smaller models reduce cloud compute, serving most query volume at dramatically lower cost.
Get to market faster. SLMs fine tune quickly and deploy easily, so you can iterate without waiting for large model infrastructure.
Stay lean, stay local. Many SLMs run on commodity GPUs, consumer laptops, or edge devices, making them viable for privacy-sensitive or offline scenarios.
Own your domain advantage. Fine tuned SLMs trained on proprietary datasets become unique assets that strengthen your competitive moat.
4. Practical Founder Action Plan
A. Audit Your Workflow
Identify repetitive, predictable steps such as form parsing, classifying emails, or generating templated text.
Flag the high-complexity cases where true LLM reasoning is required.
B. Prototype with SLMs
Select an SLM under 10B parameters and fine tune it using LoRA or adapters for one high-frequency task.
C. Monitor and Route
Deploy the SLM into production and monitor confidence scores, error rates, and latency. Route low-confidence cases to an LLM selectively.
D. Iterate and Expand
Add more SLMs, each fine tuned for specific subtasks such as summarization, intent detection, or structured outputs. Use your LLM strategically.
E. Push to Edge or On-Premise
For data sovereignty or cost savings, deploy fine tuned SLMs to on-prem infrastructure or directly to client devices. Reserve LLM usage for central workloads.
5. The Strategic Play: Lean, Focused, Extendable
Starting with smaller models does not mean settling for less. A lean SLM core, fine tuned to your business context, gives you momentum: cheaper, faster, and often more accurate than generic large model pipelines. When your product roadmap demands deeper reasoning or broader versatility, you can extend selectively with LLMs. Until then, save compute, reduce cost, and move faster.
At NorthBound Advisory, we work closely with startups to turn these strategies into practical results. Whether you are a founder making your first AI architecture choices, a VP of Engineering looking to optimize costs, or a CTO shaping a hybrid model roadmap, we can help you navigate the trade-offs and design what fits your business. If you are exploring how small language models and large models can be combined effectively, our team is here to coach, guide, and build alongside you.