
LLM Pricing Explained: How To Avoid Surprise Bills And Still Get Great Results
LLMs feel “free” when you are on a chat screen, until your app scales or you start processing real documents. This guide gives you a clear mental model for how pricing works, shows real numbers across popular models, and gives you playbooks for three common audiences: coders, API builders, and daily power users.
The 3 things that drive your bill
Tokens
All providers bill by tokens. Inputs and outputs both count. Longer prompts and longer answers cost more. Most providers also treat images and audio as tokens once they are encoded, so multimodal work is not “free.” OpenAI documents that images are converted to tokens and billed at model token rates, and it lists separate image token rates for some endpoints.
Context
Long conversation history or large files must be reprocessed to answer the next turn. Some vendors now offer prompt caching so a repeated system prompt or static context is cheaper on subsequent calls.
For example, OpenAI lets you flag a block of text (like a system prompt or instruction set) as cached, so it is billed at a much lower rate on repeat use. Anthropic, Google Gemini, and Mistral also support caching in similar ways, with reduced pricing for reusing static context.
Practical takeaway: Cache long, unchanging parts of your prompts (like company policies, style guides, or coding rules) and only send the dynamic part each time. This simple tweak can cut input costs by up to 80–90 percent when you reuse the same setup across many calls.
Mode
Batch calls and “mini” models are cheaper. Several platforms offer Batch at roughly half price for asynchronous jobs. Google’s Gemini Batch Mode and Mistral’s Batch both advertise a 50 percent discount, and OpenAI’s Batch API advertises 50 percent off inputs and outputs.
What does it actually cost right now
Prices change, so here are current published numbers for popular models. All prices are per 1M tokens in USD, sorted from most expensive to least expensive (based on output cost).
Frontier and mainstream models
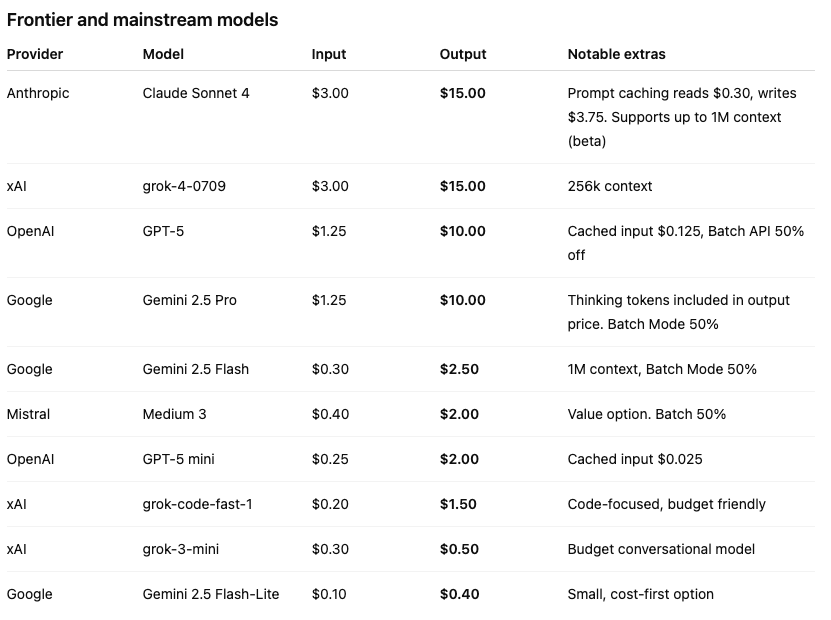
Sorted from most expensive to least expensive
Open models through fast inference providers
Not all LLMs come from the big frontier labs. A growing number of companies specialize in fast inference providers. These platforms host open-source models and focus on ultra-low latency and lower cost per token. They do not train the models themselves, but they make them available at high speed and at a fraction of frontier prices.

Cost recipes for three audiences
A) If you write code with AI
Target experience
Fast iterations, many small calls, occasional deep reasoning.
Recipe
Default to a code-tuned small or mid model for completion and local refactors. Escalate to a frontier model only for design reviews or multi-file refactors.
Cap output length for completions. Ask for diffs or patch blocks instead of full files.
Cache your system prompt plus project rules.
Use Batch for background static analysis or large-scale test generation.
Reality check math
Suppose 20 loops, each with 2k input tokens and 4k output tokens. Costs can range from more than a dollar with frontier models to less than a cent with the smallest open models.
B) If your app makes lots of API calls
Target experience
Stable quality, predictable cost at scale.
Recipe
Tiered router: small model for classification, extraction, or tool selection, mid model for ordinary queries, frontier only for high-stakes tasks.
Aggressive prompt hygiene: strip whitespace, boilerplate, and duplicate context.
Sliding window memory: keep only what is needed for the next answer. Long transcripts are expensive because the full context keeps getting reprocessed.
Cache static context such as logos, product specs, or policies.
Use Batch for nightly jobs such as scoring, summarization, or index refreshes.
Cap output length and favour structured outputs. JSON schemas or strict formats reduce token waste.
C) Everyday ChatGPT Power Users
Target experience
Great answers without ballooning usage in your workflow.
Recipe
Ask for short formats by default: bullet list, numbered plan, or a table.
When you upload PDFs, pre-clean them: remove boilerplate, blank pages, repeated headers and footers. This content still gets tokenized and billed when converted from PDF or OCR.
For long reports, ask for “map first, zoom later”: get section outlines first, then dive deeper.
Use summaries and excerpts rather than full rewrites unless needed.
PDFs and large documents: why the bill spikes
When you upload a document, the platform converts it to text tokens. Scanned pages go through OCR, then that text is tokenized. Repeated headers, footers, and whitespace still count. This is why cleaning files and chunking them by section keeps costs in check.
Picking the right model for your task
Use small or budget models for routing, classification, extraction, simple Q&A, and autocomplete.
Use mid models for most app UX where latency, cost, and quality need balance.
Use frontier models when the task is ambiguous, multi-step, or high stakes.
Five cost controls that work instantly
Right-size the model. Use the smallest model that meets the quality bar.
Trim the prompt. Remove greetings, filler, and repeated instruction blocks.
Constrain outputs. Ask for a word count or a schema.
Cache what never changes, like your system prompt, glossary, or policies.
Batch overnight. If it does not need to be real time, run it in batch.
Conclusion
You do not need a giant model for every call. Most teams save 60 to 90 percent by using a tiered approach, prompt hygiene, caching, and batch for offline work.
If you want help optimizing your LLM spend, NorthBound Advisory it's here to help.